 ©2023 Yann Guidon
all documentation published under CC BY-NC-SA 4.0 license.
Dedicated to all those who RTFM.
©2023 Yann Guidon
all documentation published under CC BY-NC-SA 4.0 license.
Dedicated to all those who RTFM.
Created sam. 30 sept. 2023 21:52:48 CEST by whygee@f-cpu.org Version sam. 16 déc. 2023 15:19:49 CET PRELIMINARY / WORK IN PROGRESS Things evolve and could be changed without notice. Check the latest news and updates at ygrec8.com and download the latest version from src.ygrec8.com or if you prefer git : gitlab.com/fhwd/ygrec8
Along with this document, you should also read:
This manual is a first glance at the YGREC8, its architecture, its programming model, its design, presenting the overall principles and goals, without going too deep into the details because they might change with later revisions and generations. It summarises six years of exploration, enhancements, adjustments, failed and successful attempts, and the choices and the compromises that have stood up so far while keeping the goals and constraints in mind. At the time of writing, there is no place for bikeshedding, feature creep or considering alternatives. The YGREC8's definition must be frozen and implemented, at least in a first working version.
The YGREC8 is a minimalist 8-bit microprocessor core. It is meant to be the smallest possible baseline for a microcontroller with the minimum number of gates, while still being useful and convenient to write code for. Despite the tiny code space, it does not try to squeeze all the code density in the world, since the development time and complexity would increase (for example, the "ADD Imm4 carry trick" has been deprecated). And too many quirks would make the YGREC8 a pain to use in practice. Unlike some more classical and recent microcontrollers and microprocessors, the YGREC8's ISA is not driven by a deep analysis of compiler-generated listings, but by the good and bad experiences of programming these. Sometimes you don't understand or need a feature, another time you wish you had a very simple and trivial one, and a balance had to be found under strict size constraints. YGREC8 is far from perfect but it is meant to work well enough and be convenient to implement.
The YGREC8 reuses features as much as possible to remain tiny: exploiting corner cases (such as with the CALL opcode becoming OVL) enhances the system while adding the fewest gates. The core could do the work of a PIC16F for example, without being as contrieved or awkward (hopefully). It is still purposefully limited: if you need more (performance, room, speed or features), use a better and larger system such as the YASEP microcontroller.
Indeed, the YGREC8's architecture is mostly inspired by the YASEP, shaven to its bare minimum with only 8 registers, including PC. With its orthogonality and in the absence of LOAD, STORE, BRANCH, or even multi-byte words, the instruction set contains only 20 instructions and the bare core uses about 600 3-input gates (not counting memory blocks). This quickly increases as you add features and peripherals.
The core is simple enough that focus can switch to:
Let's emphasize this aspect again. Though performance is not forgotten, it is not designed to be fast or powerful, but small, useful, efficient (low resources, energy-conscious) and easy to implement. It's at least "good enough" to work, so you can implement simple games like Tetris, Snake or Pong without fearing a mental breakdown. It is an ideal companion core for a more complex processor: it would handle hardware events, manage interrupts, implement a convenient bootloader, detect button presses, handle crude sound effects or check the environment's health (temperature, power...).
The unspoken assumption here is that the whole project, its development, the files, the team, follow the traditions and ethos of the Free Software and Open Source Software communities. The YGREC is a Free HardWare Design, using Copyleft licences and free from patents to allow anyone to use it and participate. Unlike the RISC-V project, you are encouraged to "give back" and publish all your enhancements, so others can benefit from them just as you benefitted in the first place. While some proprietary software might be required here and there, they are avoided as much as possible, so the source code can really be freely used. This also means a strong adherence to industry standards and practices (YGREC8 uses VHDL extensively).
Assembly language is required to pack enough useful data and programs in the very tight space available to the core. Programming the Y8 is a bit different and no compiler is available yet but this manual will show it's not hard.
Happy reading !
The YGREC8 is the result of the reduction of several experimental architectures, such as the YASEP and the YGREC16. It is inspired by RISC ideas supplemented by some Processor Design Principles. There might even be a trace of CDP1802 somewhere.
The YGREC8 implements several independent addressing spaces:
YGREC8 uses a Harvard organisation for several reasons:
Among other features, the instruction set:
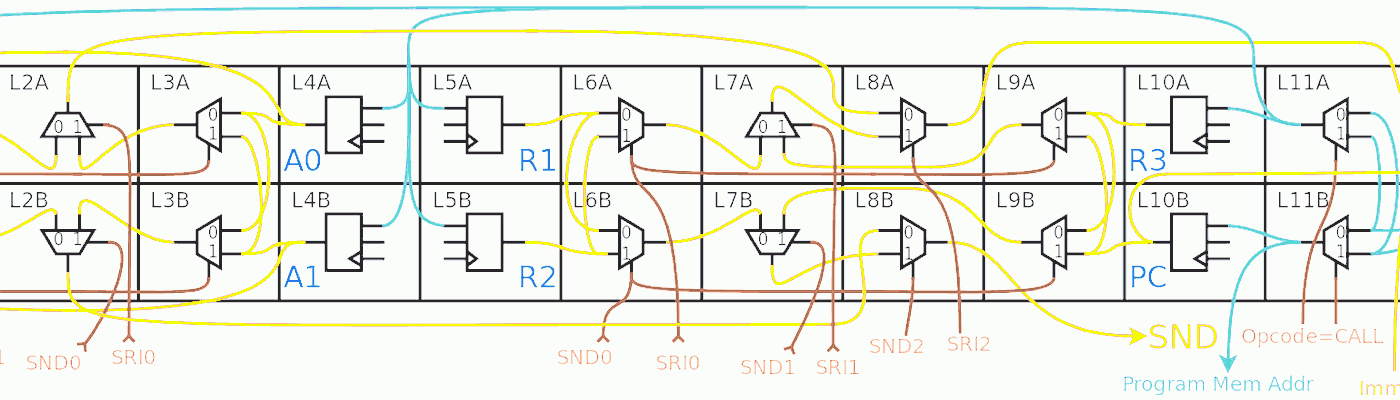
To accommodate this, the register set has 8 registers of 4 types, with the following map:
000 D1 \__ Data Memory window 1 001 A1 / 010 D2 \__ Data Memory window 2 011 A2 / 100 R1 \ 101 R2 >--- 3 "normal" registers 110 R3 / 111 PC
The instruction word fits in 16 bits by using only two 3-bit register addresses, YGREC8 is initially a 1R1W machine (like x86) instead of the more RISCy big brothers, to remove one field and save coding space. This is extended, when needed, by using the prefix PF to override the destination address of the following instruction. The two default register address fields are:

The instruction format is designed to keep all the fields as aligned as possible, to reduce the decoding logic and routing multiplexers. For example, all the Least Significant Bits of the constant fields fall on the same place (bit 3). SND is the default register field when no other value is needed and doesn't move, just like the main opcode field (bits 15:12). Some non-core opcodes have their functions encoded in place of the condition field when it is not required, to save some space. Thus the encoding can't be totally orthogonal because of the size constraints and only the most common opcodes have the full set of options, while infrequent operations don't have the 8-bit immediate mode or no condition at all.
Here are more explanations about the fields :

As of this version, there are 19 main opcodes, plus INV, and some aliases like OVL, HLT and NOP. Most share two instruction forms : either an IMM8 field, or a source & condition field. The source field can also be a register or a short sign-extended immediate field that is 4 bits wide only, but it is essential for conditional short jumps or increments/decrements.
The main opcode field has 4 bits and the following values:
These core opcodes are predicated and update the Zero and MSB flags. The SRI operand can be Imm8, Imm4 or Register:
0000 OR SND = SND | SRI 0001 XOR SND = SND ^ SRI 0010 AND SND = SND & SRI 0011 ANDN SND = ~SND & SRI
These core opcodes are also predicated. They update the Carry, Zero and MSB flags. The SRI operand can be Imm8, Imm4 or Register:
0100 CMPU -SND + SRI (unsigned) 0101 CMPS -SND + SRI (signed) 0110 SUB SND = -SND + SRI 0111 ADD SND = SND + SRI
Taken with the boolean group, the SND operand is XORed with ~b15 & ( b14 ^ (b13 & b12) ) of the instruction word (this explains why ADD is last in the list).
These last core opcodes complete the list of necessary instructions. Only SET and CALL are predicated and can use the Imm8, Imm4 or Register operands. IN and OUT can only use the IMM9 immediate field.
1000 SET SND = SRI (formerly known as MOV) 1001 CALL SND = PC+1 ; PC = SRI (also maps to OVL and HLT when SND=PC) 1100 IN SND = IO[imm9] 1101 OUT IO[imm9] = SND 1110 PF Prefix : change default behaviour for the next instruction.
The following opcodes are not essential but would be very useful in certain situations. They share the same 101x opcode prefix and don't support the Imm8 or condtion fields. I/R2 is supported so SRI can be a register (bit 6 is ignored!) or a 4-bit immediate value.
These opcodes update the Zero and MSB flags. Shift direction is given by the sign of shift: 0001 to 0111 shift left (multiply by power of two) and 1001 to 1111 shift right (divide by a power of two). 0000 and 1000 do nothing. The higher half of the SRI register operand is ignored.
10100x000 SH : SND = SND shifted by SRI bits 10100x001 SA : SND = SND arithmetic-shifted by SRI bits 10100x010 RO : SND = SND rotated by SRI bits 10100x011 RC : SND = SND rotated by SRI bits through the Carry flag (updates it).
These opcodes read into the program memory, where constant tables could be read in-place or stored before being moved to data memory for example. This is a bit more elegant and 2× denser than the PIC16's RETLW hacks. This increases the complexity of the core's scheduling but it's a smaller price to pay when it is really needed.
10100x100 LDCL SND = lower byte PM[SRI] 10100x101 LDCH SND = higher byte PM[SRI]
TODO: LDCC selects the high/low byte with the carry flag for example
The YGREC8 has room for more 1R1W opcodes in the extended range 101x, without the Imm8 or condition features.
However, new opcodes should not affect the core's scheduling or pipeline. It could be a single-bit multiplication or division step passing through the ALU. However, complex operations like full-word multiplication or division are better suited for the I/O register space. Don't clutter the core, Keep It Simple.
As mentioned in other places, some opcodes can have corner cases, which get their own opcodes:
More might appear soon.
For the first 10 opcodes, the COND field has either 3 bits (when using a 4-bit immediate operand) or 4 bits (register operand), the later is added to directly test binary input signals. These 4 extra signals (called B0, B1, B2 and B3) may come from outside pins or internal peripherals, depending on user-defined configuration. The source could even be selected on the fly with a big multiplexer (configured by a set of IO registers).
All conditions can be negated by the N field. There are 4 basic and common conditions and 4 extended ones:
- Always - C (Carry flag) - S (Sign, MSB of the last computation) - Z (Zero, all bits cleared) - B0, B1, B2, B3 (only in Register-Register form)
(notice the mnemotechnic trick: the condition names ACSZ are in alphabetical order)
The opcode map is organised along these two rules:
This creates the following table, when using the Imm4 operand:
000 Never (instruction is not executed) 001 Carry=0 010 Sign=0 (positive signed number) 011 Zero=0 (last result had at least on set bit) 100 Always (default: instruction is executed) 101 Carry=1 110 Sign=1 (negative signed number) 111 Zero=1 (last result had all bits cleared)
When using a register operand, the LSB of the condition selects either the internal condition flags or one of the four external sources. The bit 6 of the instruction (COND field's LSB) is ANDed with the negated I/R2 flag at bit 10, so the extended conditions are disabled in Imm4 mode:
0000 NEVR Never (instruction is not executed or committed, like a NOP) 0001 IFN0 B0=0 0010 IFNC Carry=0 0011 IFN1 B1=0 0100 IFNS Sign=0 (positive signed number, aliased as IFP?) 0101 IFN2 B2=0 0110 IFNZ Zero=0 (last result had at least on set bit) 0111 IFN3 B3=0 1000 ALWS Always (the default condition so writing it is not required) 1001 IF0 B0=1 1010 IFC Carry=1 1011 IF1 B1=1 1100 IFS Sign=1 (negative signed number) 1101 IF2 B2=1 1110 IFZ Zero=1 (last result had all bits cleared) 1111 IF3 B3=1
The bold keywords are the corresponding assembly language keywords, chosen to fit in 4 characters (which is a nice touch for electromechanical input or display).
The YGREC8 prioritises simplicity over coding density. It is a delicate balance: in pure RISC tradition, keeping the core simple makes it fast and manageable. Orthogonality lets many instructions share the same circuits and reduces the coding complexity. Increasing density (to improve program size) would complicate the decoder and the programming experience. Typically, RAM cells are smaller than logic cells so it's a somewhat sensible argument.
The orthogonality has its downsides though, in particular with the degenerate combinations as well as absurd ones. They are handled either as "don't care" or errors, as potential future extensions or as invalid conditions.
Total : 4096 + 4096 + (4096-128) + (4096-(6*192)) = 15104 invalid opcodes. Many of them might be used in the future.
The above census provides the data required to write the boolean equation that flag an instruction as invalid. Here it is in VHDL:
--TRAP if
OPCODE=Op_RSVD
or OPCODE=Op_INV
or (OPCODE=Op_PF and -- PF opcode with IR or IR2 or SRI not cleared
instruction_word(11 downto 10) & instruction_word( 5 downto 3) /= "00000")
or (OPCODE=Op_EXT1 and
(( instruction_word(11)='1' or instruction_word(9 downto 8)="11" ) -- 10 EXT1 reserved opcodes
or ( instruction_word(10)='0' and instruction_word(6)='1'))) -- unused bit when SRI
Overall, about one fourth of the opcode space can be reassigned in the future, which is a fair proportion for a future-proof design. Funky features should be relegated to the IO register space but there is some space left for regular circuits that fit the scheduling and simplicity constraints of the core.
To be continued...
Now have a look at the YGREC8's Integration manual, the Programming manual or the Assembly Language manual.